2회차
👉 노션에서 자세히 보기 (opens in a new tab)
2️⃣ 2회차 공지사항 (opens in a new tab)
Check In 🚪
Join /functional-programming's Cuckoo Timer! (opens in a new tab)
민수(김)
- 희망찬
- 디자인 시스템: seed-design(당근마켓) 연락
- 긍정적인
- 연차: 카페, 걷기 하니까 기분 좋아요
수림
- 긍정적인
- 신규 프로젝트 재밌을 것 같다.
- 집중하는
- 신규 프로젝트 관련해서 공부가 필요할 것 같아서
- 어떤 공부?! 자바 → Node 마이그레이션 (Nest, nodejs)
- 신규 프로젝트 관련해서 공부가 필요할 것 같아서
종현
- 편안한
- 지난 주에는 격분,,, 작업만 하면 되는 상태 프로세스 개선의 여지가 보여서 더 좋은 것 같다.
- 희망찬
- 마이스터 고등학교 연사
- 600명 앞에서
- 주제: 라이브러리 얘기 (개인적인 희망) 창업 했던 경험이 있어서, 개발자로 전향하게 된 계기 ”시니어도, 세계 유명한 개발자도 사람이다.” 이메일로 초청받았었다.
- 트위터, AWS, 고종현 let’s go
- 후기 꼭꼭
- 마이스터 고등학교 연사
예진
- 재미있는
- 코드리뷰: 오랜만에 재밌어
- 들뜬
- 헬스 PT상담
민수(박)
- 마음이 불편한
- 저번 주 참여를 못하구 리프레시 휴가를 다녀왔는데 바로 회사 워크샵을 가게 되었다. 스터디에 많은 시간을 못쓰게 된 것 같아서 (일정이 꼬여서 ㅠㅠ)
- 감사하는
- 지금 회사에 다시 감사하게 된 마음을 갖게 되었다.
이론 파트 📝
✅ Chapter: Ch 5 ~ Ch 7 Page: 87 p ~ 165 p
좋았던 내용, 또는 논의하고 싶었던 내용을 기반으로 공유하고 싶은 이론 파트를 정리해보아요!
민수(김)
- 좋았던 부분
- Ch5 더 좋은 액션 만들기 💡 원칙: 압묵적 입력과 출력은 적을수록 좋습니다. 의 원칙이 인상적이었다. 기존에 함수형 프로그래밍을 공부할 때는 실무에 어떻게 적용할지에 대해서 와닿지 않았다면, 책에서 원칙을 알려주고 이렇게 예제로 설명하는 부분이 너무 와닿았다.
- Ch6 변경 가능한 데이터 구조를 가진 언어에서 불변성 유지하기
- 논의하고 싶은 부분
-
테스트를 작성할 때 모든 입력의 상황을 가정하고 명세를 작성하는지?
자세히 보기
describe('add', () => { it('should return vaild value', () => { expect(add(2,3)).toBe(5) expect(add(2,-3)).toBe(-1) expect(add(2,0)).toBe(2) }) })위 예시에선 양수, 음수, 0 의 케이스만 테스트하고 있습니다. 두 자릿수, 세 자릿수, Infinity 등의 경우는 테스트하고 있지 않지만 머릿속에서 어느정도 당연하게 통과할거라는 믿음이 있습니다. 이런 걸 테스트 케이스로 작성하는 게 맞을지, 아니면 이런 영역은 QA의 영역이라고 생각하시는지 궁금합니다.
-
함수를 계산으로 쪼갰을 때 (순수함수로 분리했을 때) 오히려 귀찮아지거나 불편했던 경험은 없으셨는지
자세히 보기
책에서는 다음과 같은 장점이 있다고 합니다.
- 재사용하기 쉽다.
- 유지보수하기 쉽다
- 테스트하기 쉽다.
저도 공감하기도하고, 장점으로 뽑힌 내용들이 장기적으로 봤을 때는 맞지만 당장의 문제를 해결하기 위해 너무 많은 설계의 시간을 쓰는 건 아닐까 하는 생각이 드는 순간들이 있었던 것 같습니다.
예를 들어, 당장 재활용될 가능성이 전혀 없는 함수를 순수함수로 분리하면서 파일과 테스트 파일이 별도로 따로 생기고 그걸 작성하는 시간이 또 드는게, 유지보수를 위해 당장의 문제를 해결하는데 병목이 생기는 건 아닐까 라는 생각이 들었습니다.
위 사례에 적합한 예시인지 모르겠지만 최근에 제가 고민했었던 내용이 있어서 의견을 듣고 싶었습니다.
최근에 DS를 설계하는 과정에서 compound로 조합해서 사용할 수 있게, 설계하는 방법을 적용하고 있었는데, 디자이너 분과의 논의 과정이 있었습니다.
민수: 버튼 안에 아이콘 말고 다른 요소가 들어올 수 있는거죠? 그럼 간격만 정의해주세요, 안에 뭘 그릴지는 개발자가 직접 넣을 수 있도록 처리하겠습니다! → children 으로 받게하고 gap만 주겠다. 디자이너: 아이콘 말고 다른 요소가 들어올 수는 있지만, 그럼 개발자가 임의로 디자인 시스템을 수정해서 사용할 수도 있는건데, 그건 디자인 시스템을 활용한다는 느낌이 전혀 없다. 만약 아이콘 말고 다른 요소가 들어올 수 있다면 그 때 말씀 드리겠지만, 그렇게 디자인 시스템이 수정될 경우도 없을거다.제가 알고 있는
사전 결정 최소화의 원칙과는 너무 상이한 이야기였습니다.DS는
사전에 결정을 최대한 많이하고 그걸 규격화해서 시스템 안에서 사용하는 환경이라고 생각해야하는건가..? 라는 생각이 들면서 컴파운드 패턴을 덜어내야 하는건가에 대한 생각이 드는 순간이었습니다. -
얕은 복사를 의도적으로 활용해본 경험이 있으신가요?
-
- 실습 문제 관련 아이디어
- 6장에서 (p122) 읽기도 하면서 쓰기도 하는 함수를 개선하는 내용이 있다.
- shift 외에도 이런 내장 함수가 있었나? 있다면 그것도 바꿔보거나 shift를 나만의 방식으로 개선해보자
- 파랑님 문제중에 deepCopy 직접 구현하는 문제가 있는데 그거 꼭 풀어보자!
- 6장에서 (p122) 읽기도 하면서 쓰기도 하는 함수를 개선하는 내용이 있다.
수림
좋았던 부분
암묵적 입력과 출력은 적을수록 좋다 (p.91)
암묵적 입력: 인자가 아닌 모든 입력암묵적 출력: 리턴값이 아닌 모든 출력, 쓰기 행위계산: 암묵적 입력과 출력이 없는 함수다른 컴포넌트와 강하게 연결된 컴포넌트- 암묵적 입력과 출력이 있는 어떤 함수
- 다른 곳에서 사용할 수 없기 때문에
모듈이 아님
모듈화된 컴포넌트- 명시적 입력과 출력이 있는 어떤 함수
- 명시적 입력과 출력은 모듈에 있는 커넥터와 같다
암묵적 입력과 출력있을 때의 어려운 점
- 암묵적 입력과 출력이 있는 함수는 다른 곳에 영향을 주기 때문에 조심해서 사용해야 한다.
- 암묵적 입력과 출력이 있는 함수는 아무 때나 실행할 수 없기 때문에 테스트하기 어렵다.
계산 분류하기 (p.97, p.102)
- 장바구니 구조 (cart에 대한 동작)
- 제품에 대한 구조 (item에 대한 동작)
- 비즈니스 규칙에 대한 함수
- 유틸리티 함수
설계는 엉켜있는 코드를 푸는 것이다 (p.98)
- 함수를 사용하면 관심사를 자연스럽게 분리할 수 있습니다
- 함수는 인자로 넘기는 값과 그 값을 사용하는 방법을 분리합니다.
좋은 설계
- 재사용하기 쉽다
- 함수는 작으면 작을수록 재사용하기 쉽다
- 하는 일도 적고 쓸 때 가정을 많이 하지 않아도 된다
- 유지보수하기 쉽다
- 작은 함수는 쉽게 이해할 수 있고 유지보수하기 쉽다.
- 코드가 작기 때문에 올바른지 아닌지 명확하게 알 수 있다
- 테스트하기 쉽다
- 작은 함수는 테스트하기 좋다
- 한 가지 일만 하기 때문에 한 가지만 테스트하면 된다.
- 함수에 특별한 문제가 없어도 꺼낼 것이 있다면 분리하는 것이 좋다
함수의 행동을 부분적으로 나누기 (p.99)
function addItem(cart, name, price) {
const newCart = cart.slice() // 1. 배열을 복사
const item = { name, price } // 2. item 객체를 생성
newCart.push(item) // 3. 복사본에 item을 추가
return newCart // 4. 복사본을 반환
}비즈니스 규칙과 장바구니 기능의 차이점 (p.103)
- 비즈니스 규칙
- 서비스에서 운영하는 특별한 규칙
- 서비스가 달라지면 달라질 수 있음
- 장바구니 기능
- 대부분의 전자상거래 서비스에서 사용하는 일반적인 개념
- 동작방식이 서비스와 별개로 모두 비슷
동작을 읽기, 쓰기 또는 둘 다로 분류하기 (p.111)
- 읽기
- 데이터를 바꾸지 않고 정보를 가져온다
- 데이터를 바꾸지 않는다
- 쓰기
- 데이터를 바꾼다
카피-온-라이트 원칙과 세 단계 (p.112)
불변성 법칙 == 카피-온-라이트
카피-온-라이트 규칙 (아래의 불변성을 유지하면서 값을 바꿀 수 있는 세 단계를 구현하면 카피-온-라이트로 동작)
- 복사본 만들기
- 복사본 변경하기
- 복사본 리턴하기
카피-온-라이트 함수는 읽기이다 (p.112)
데이터를 바꾸지 않았고 정보를 리턴했기 때문에 읽기이다. (쓰기를 읽기로 바꿈)
불변 데이터 구조를 읽는 것은 계산입니다 (p.131)
- 액션
- 변경 가능한 데이터를 읽는 것
- 계산
- 불변 데이터 구조를 읽는 것
- 쓰기
- 데이터를 변경 가능한 구조로 만듦
- 어떤 데이터에 쓰기가 없다면 생성 이후 바뀌지 않으므로 변경 불가능한 데이터 (불변 데이터)
- 쓰기 → 읽기로 바꾸면 코드에 계산이 많아진다
얕은 복사와 구조적 공유 (p.133)
- 얕은 복사
- 데이터 구조의 최상위 단계만 복사하는 것
- 구조적 공유
- 두 중첩된 데이터 구조에서 안쪽 데이터가 같은 데이터를 참조
- 데이터가 바뀌지 않는 불변 데이터 구조라면 구조적 공유는 안전하다
- 구조적 공유는 메모리를 적게 사용하고 모든 것을 복사하는 것보다 빠름
방어적 복사는 원본이 바뀌는 것을 막아줍니다 (p.150)
안전지대 안으로 들어온 데이터: 깊은 복사본을 만들고 원본은 버림안전지대 밖으로 나가는 데이터: 깊은 복사본을 만들어 내보냄
방어적 복사 (p.151)
- 정의 및 특징
- 데이터를 변경할 수도 있는 코드와 불변성 코드 사이에 데이터를 주고받기 위한 원칙
- 데이터가 바뀌는 것을 완벽히 막아 불변성을 지킬 수 있다
- 원본이 바뀌지 않도록 막아주어 방어적이라고 한다
- 목적
- 안전지대에 불변성을 유지하고 바뀔 수도 있는 데이터가 안전지대로 들어오지 못하도록 하는 것
- 동작 방식
- 들어오고 나가는 데이터의 복사본을 만드는 방식으로 동작
방어적 복사 규칙 (p.152)
깊은 복사: 위에서 아래로 모든 계층에 있는 중첩된 데이터 구조를 복사
- 데이터가 안전한 코드에서 나갈 때 복사하기
- 불변성 데이터를 위한 깊은 복사본을 생성
- 신뢰할 수 없는 코드로 복사본을 전달
- 안전한 코드로 데이터가 들어올 때 복사하기
- 변경될 수도 있는 데이터가 들어오면 바로 깊은 복사본을 생성하여 안전한 코드로 전달
- 복사본을 안전한 코드에서 사용
비공유 아키텍처 (p.156)
모듈이 서로 통신하기 위해 방어적 복사를 구현한 아키텍처
- 모듈이 어떤 데이터의 참조도 공유하고 있지 않음
카피-온-라이트 vs 방어적 복사 (p.158)
| 카피-온-라이트 | 방어적 복사 | |
|---|---|---|
| 언제 쓰나요? | 통제할 수 있는 데이터를 바꿀 때 사용 | 신뢰할 수 없는 코드와 데이터를 주고받아야할 때 사용 |
| 어디서 쓰나요? | 안전지대 어디서나 사용 가능 | 안전지대의 경계에서 데이터가 오고 갈 때 사용 |
| 복사 방식 | 얕은 복사 | 깊은 복사 |
| 규칙 | 1. 바꿀 데이터의 얕은 복사본을 생성 |
- 복사본을 변경
- 복사본을 반환 | 1. 안전지대로 들어오는 데이터에 깊은 복사를 생성
- 안전지대에서 나가는 데이터에 깊은 복사를 생성 |
논의하고 싶은 부분
-
본인이 코드 스멜을 느끼는 순간 (p.88)
중복이 항상 나쁜 것은 아니지만 코드에서 나는 냄새입니다. 코드의 냄새는 나중에 문제가 될 수 있습니다. 코드의 냄새는 더 큰 문제를 미리 알려줍니다. -
함수의 동작을 바꿨기 때문에 엄밀히 말하면 리팩터링이라고 할 수 없습니다. (p.89)
// AS-IS const getsFreeShipping = (total, itemPrice) => { return itemPrice + total >= 20 } // TO-BE const getsFreeShipping = (cart) => { return calcTotal(cart) >= 20 }- 그렇다면 피처인가? 어떻게 말할 수 있을까?
-
실습 문제 관련 아이디어
- 이번장은 책에 나온 실습 문제들이 많아서 풀어보는 것도 좋을 것 같습니다!
종현
- 논의하고 싶은 부분
- 압묵적 입력과 출력은 적을수록 좋습니다.
- hook은 암묵적 입력일까?
- useContext
논의 내용
- useContext를 사용하는 건 압묵적 입력일 것 같다. 에러를 던지는 게 맞을까?
- 민수: 에러를 던지는 게 맞다고 생각하긴 하지만, react에서 제공하는 예외처리가 defaultValue로 제공하는 것 같다.
- 수림: 보는 관점에 따라 다른 것 같기는 하다. hook은 내부 구현체가 있는 안전지대 안의 데이터를 안전하게 수정할 수 있게끔 해줄 수 있는 방어적 복사가 아닐까?
- 민수(박): hook이 해줄려는 목적 자체가 상태를 관리하는 것이기 때문에 압묵적 입력과 출력이 좋다는 경우는 또 아니지 않을까
- useContext를 사용하는 건 압묵적 입력일 것 같다. 에러를 던지는 게 맞을까?
- useSelector
const Foo = () => { const todo = useSelector((store)=> store.todos)); const [state, setState] = useState(); } - 불변성을 지키기 위해 불변성을 유지해야하는 부분은 타입스크립트에서는 먼저 readonly를 사용하자?
const theme = { colors: { red: ... } } as const
- useContext
예진
- 좋았던 부분
- 5장: item에 대한 부분도 따로 함수로 분리하는 리팩토링 방식이 인상 깊었다. 이렇게 하면, 나중에 item의 데이터구조가 바뀌더라도, item 영역만 신경쓸 수 있다는 점이 좋은 것 같다.
- 7장: 방어적 복사를 하려면, 함수에 들어오기 전후에 데이터를 깊은 복사를 해야 한다 한다. 왜 데이터를 바깥으로 내보내야할 때에도 깊은 복사를 해야할까 하는 의문이 들었다. 생각해보니, 안전지대 바깥은 언제 어디서 어떻게 데이터가 변경될지 모르기에, 데이터를 깊은 복사 해줘야 함을 이해할 수 있었다.
- 논의하고 싶은 부분
-
dropFirst, dropLast는 사실 shift, pop을 한 번 더 감싼 형태이다. 이런 식으로 JS에서 제공하는 기본적인 유틸까지 한 번 더 감싼 형태를 현업에서 적용하고 있는지? 적용하고 싶은지? 한다면, 어떻게 팀원들을 설득할 것 같은지?
논의한 내용
- 수림: Math.floor 같은 숫자 관련 기본 메서드를 랩핑해서 사용하는 건 이해가 가지만 Array 관련한 부분을 추가로 랩핑하는 건 좀 취향차이?라고 생각이 든다.
- 민수(박): 가독성의 영역인 것 같다. 읽기와 쓰기를 같이 하는 함수는 사용하는 측에서는 자유도가 높아지지만, 제한하면 더 가독성이 더 높아진다.
- 민수(김): 한 번 더 함수로 감싸서 추상화하면, 더 가독성이 좋아진다고 생각. 한 번은 설득할 것 같다. 증명은 못하겠지만…! 가독성이 더 좋아진다고 의견을 어필할 것 같다. 팀원들이 ~~하면 ok 하고 맞춰갈 것 같다. 나에게만 DX이기에, 다른 분들의 의견을 고려할 듯하다. 강한 어필은 ㄴㄴ.
- 종현: 팀원이 강하게 주장해줬으면 하다. 왜 좋다고 생각하시는지 의견이 궁금하다.
// As-is type ClassNameValue = string | null | undefined | 0 | false; export const classNames = (classes: ClassNameValue[] | ClassNameValue) => { if (Array.isArray(classes)) { return classes.filter(Boolean).join(' '); } else { return classes || ''; } }; // To-be const isArray = v => Array.isArray(v) const getTruthy = (arr) => arr.filter(Boolean); export const classNames = (classes: ClassNameValue[] | ClassNameValue) => { if (isArray(classes)) { return getTruthy(classes).join(' '); } else { return classes || ''; } }; -
읽기 함수와 쓰기 함수를 분리하는 편이신지? 분리하신다면, 보통 어떤 네이밍 컨벤션을 쓰시는지?
논의한 내용
- 예진: 우리는 보통 get을 붙였다.
getFirstvsfirst - 수림: get/set 을 prefix
- 민수: getTodo vs todo
- 할일 가져오기 vs 할일
- 예진: 우리는 보통 get을 붙였다.
-
민수(박)
- 좋았던 부분
- 압묵적 입력과 출력은 적을수록 좋습니다. (p.91)
- 개발할때 항상 인지하고 신경쓰기에 좀 소홀해지는 경우가 있었던 것 같은데, 다시 한번 생각해볼 수 있어서 새삼 좋았다.
- 쓰면서 읽기도 하는 함수인 shift 함수를 분리하는 예제 (p.123)
- shift 함수를 코테할때 많이 썼었던 기억이 있는데, 당시에는 읽기와 쓰기 동작을 구분해볼 생각은 못해봤었던 것 같다. 근데, 가독성이 깔끔해지는 것을 보고 새삼 놀랐다.
- 압묵적 입력과 출력은 적을수록 좋습니다. (p.91)
- 논의하고 싶은 부분
- 다들 얕은 복사 많이 사용하시나요?
- 저 같은 경우에는 레퍼런스 참조로 인해 사이드 이펙트가 발생하는 경우처럼 의도적으로 깊은 복사를 해야하는 경우가 아니라면(읽기만 하는 경우) 비용을 생각해서 얕은 복사를 사용하기도 하는 것 같습니다. 근데 책을 읽다보니 문득, 결국 이후에 사이드 이팩트를 발생시킬 가능성을 코드에 두고 가는게 아닌가 하는 생각이 들어서 어떤 기준을 가져야 할 지 고민되는 지점인 것 같네요.
논의한 내용
- 민수(박): 지금은 읽기만 해서 얕은 복사가 문제가 없지만, 나중에 수정할 때 쓰기를 하게 되면 원본이 훼손이 되기 때문에 사이드 이펙트가 발생할 수도 있겠다.
- 종현: 사용하지 않긴한다. 애초에 map이나 filter와 같이 사본으로 만들어주는 메소드를 사용하는 편이다.
- 민수(김): 성능 차이가 크게 나는 게 아니라면, 원본을 그냥 읽어도 되지 않을까?
- 민수(박): 원본을 수정하지 않는 선에서 할 수 있는 것들에서 깊은 복사를 하지 않는 것 같다.
- 유의미한 성능차이
- 컴퓨터가 성능이 좋고, 브라우저가 너무 좋으니 그런 걸 고려 안 해도 된다는 입장이 있다.
- 그치만 고려를 아예 안 하는 건 싫다.
논의한 내용
Ex. CSS-in-JS
- 수림: 온보딩할 때 멘토님이 해주셨던 얘기가 있다. 근본에 대해서 가르침을 받으면서 공부했었다보니, 소프트웨어를 사용하는 사람 입장에서 관습이자 체화 되어있는 게 더 좋지 않나? 라고 생각한다.
- 예진
- 최근에 컴파일러를 공부했었다.(v8)
- 이렇게 좋은 컴파일러가 있는데, 성능을 최적화하게 하기 위해 가독성을 놓치는 건..?
- lighthouse 가 경고하면 다시 한 번 생각해볼 것 같다.
- 다들 얕은 복사 많이 사용하시나요?
- 실습 문제 관련 아이디어
실습 💻
문제집 만들기
-
아이디어 스토밍 다시 보기
실습 문제는 최대한 상세하게 적어주세요!
실습 문제 예시
Q. 아래 코드를 액션, 계산, 데이터로 분리하면서 리팩터링 하는 것과 함께 아래 코드에 대한 테스트 코드를 작성해주세요!
// AS-IS
// app.ts
function convertToConditionalUpperCase(words: string[]): string[] {
let capitalized =
for (let i = 0; i < words.length; i++) {
if (words[i].length > 5) {
capitalized.push(words[i].toUpperCase());
} else {
capitalized.push(words[i].toLowerCase());
}
return capitalized;
// TO-BE
// app.ts
// app.test.ts민수(김)
문제 1
JS에서 배열의 내장 함수에는 splice가 있다.
splice를 압묵적 출력을 제거하고 명시적 출력을 활용한 순수함수로 바꿔보자수림
- Q. 아래의 코드는 책에서 소개된 등급에 맞게 쿠폰을 이메일로 보내는 요구사항을 구현한 코드입니다. 본인만의 방식으로 리팩터링 해주세요!
-
어떤 부분을 리팩터링의 기준으로 삼았는지 PR에 작성하기
- Ex. 데이터, 계산, 액션
-
코드
const subscriber = { email: "sam@pmail.com", rec_count: 16 }; const rank1 = "best"; const rank2 = "good"; function subCouponRank(subscriber) { if(subscriber.rec_count >= 10) return "best"; else return "good"; } const coupon = { code: "10PERCENT", rank: "bad" }; function selectCouponsByRank(coupons, rank) { const ret = []; for(let c = 0; c < coupons.length; c++) { const coupon = coupons[c]; if(coupon.rank === rank) ret.push(coupon.code); } return ret; } const message = { from: "newsletter@coupondog.co", to: "sam@pmail.com", subject: "Your weekly coupons inside", body: "Here are your coupons ..." }; function emailForSubscriber(subscriber, goods, bests) { const rank = subCouponRank(subscriber); if(rank === "best") return { from: "newsletter@coupondog.co", to: subscriber.email, subject: "Your best weekly coupons inside", body: "Here are the best coupons: " + bests.join(", ") }; else // rank === "good" return { from: "newsletter@coupondog.co", to: subscriber.email, subject: "Your good weekly coupons inside", body: "Here are the good coupons: " + goods.join(", ") }; } function emailsForSubscribers(subscribers, goods, bests) { const emails = []; for(let s = 0; s < subscribers.length; s++) { const subscriber = subscribers[s]; const email = emailForSubscriber(subscriber, goods, bests); emails.push(email); } return emails; } function sendIssue() { const coupons = fetchCouponsFromDB(); const goodCoupons = selectCouponsByRank(coupons, "good"); const bestCoupons = selectCouponsByRank(coupons, "best"); const subscribers = fetchSubscribersFromDB(); const emails = emailsForSubscribers(subscribers, goodCoupons, bestCoupons); for(let e = 0; e < emails.length; e++) { const email = emails[e]; emailSystem.send(email); } }
-
예진
URL의 쿼리스트링 관련 유틸 함수를 계산 을 최대한 이용하여 만들기
-
parse함수: url의 쿼리 스트링을 객체로 변환해주는 함수// test case 1 parse('foo=bar&abc=xyz&abc=123') // { // foo: 'bar', // abc: ['xyz', '123'] // } // test case 2 parse('?foo=bar&bar=baz') // { foo: bar, bar: baz } -
stringify함수: 객체를 URL 쿼리스트링으로 변환해주는 함수- 빈 객체가 주어지면, 빈 스트링 반환
- key-value 쌍이 있으면, 앞에
?추가 - value가 falsy한 것도 포함
// test case 1 stringify({ foo: 'bar', baz: ['qux', 'quux'], corge: '' }); // '?foo=bar&baz=qux&baz=quux&corge=' // test case 2 stringify({ a: 1, b: 2, c: '가나다' }); // '?a=1&b=2&c=%EA%B0%80%EB%82%98%EB%8B%A4' -
addQuery함수: 현재 URL에 쿼리 추가하는 함수- 해쉬가 있다면, 유지해야 함
- 기존 쿼리가 있다면, 유지해야 함
- 기존 쿼리와 추가하려는 쿼리의 key가 동일하다면, 기존 쿼리가 대체됨
// test case 1 addQuery('https://www.linkedin.com/', 'key', 'value') // https://www.linkedin.com/?key=value // test case 2: 기존 URL에 이미 쿼리가 있는 경우 addQuery('https://www.linkedin.com/?name=elon', 'key', 'value') // https://www.linkedin.com/?name=elon&key=value // test case 3: 기존 URL에 hash가 있는 경우 addQuery('https://www.linkedin.com/?name=elon#top', 'key', 'value') // https://www.linkedin.com/?name=elon&key=value#top // test case 4: 기존 쿼리와 추가하려는 쿼리의 key가 동일한 경우 addQuery('https://www.linkedin.com/?name=elon#top', 'name', 'musk') // https://www.linkedin.com/?name=musk#top -
deleteQuery함수: 현재 URL에서 주어진 key에 해당하는 모든 값을 제거deleteQuery('https://example.com?foo=1&bar=2&foo=3', 'foo') // 'https://example.com/?bar=2' deleteQuery('https://example.com?foo=1', 'foo') // 'https://example.com/' deleteQuery('https://example.com?foo=1#top', 'foo') // 'https://example.com/#top'
- 참고
- https://github.com/sindresorhus/query-string (opens in a new tab)
- https://slash.page/libraries/common/utils/src/querystring.i18n/ (opens in a new tab)
- https://www.linkedin.com/pulse/how-migrate-from-querystring-urlsearchparams-nodejs-vladimír-gorej/ (opens in a new tab)
- https://developer.mozilla.org/ko/docs/Web/API/URLSearchParams (opens in a new tab)
실습 풀이 및 리뷰간 논의하고 싶었던 내용
실습 문제에 대한 질문과 리뷰를 받으면서 스터디원 분들과 논의하고 싶었던 내용이 있다면 공유해주세요!
실습 문제 아이디어 스토밍
지난 주는 어떤 아이디어를 기반으로 문제를 만들었을까?
-
슬랙 스레드 스크린샷
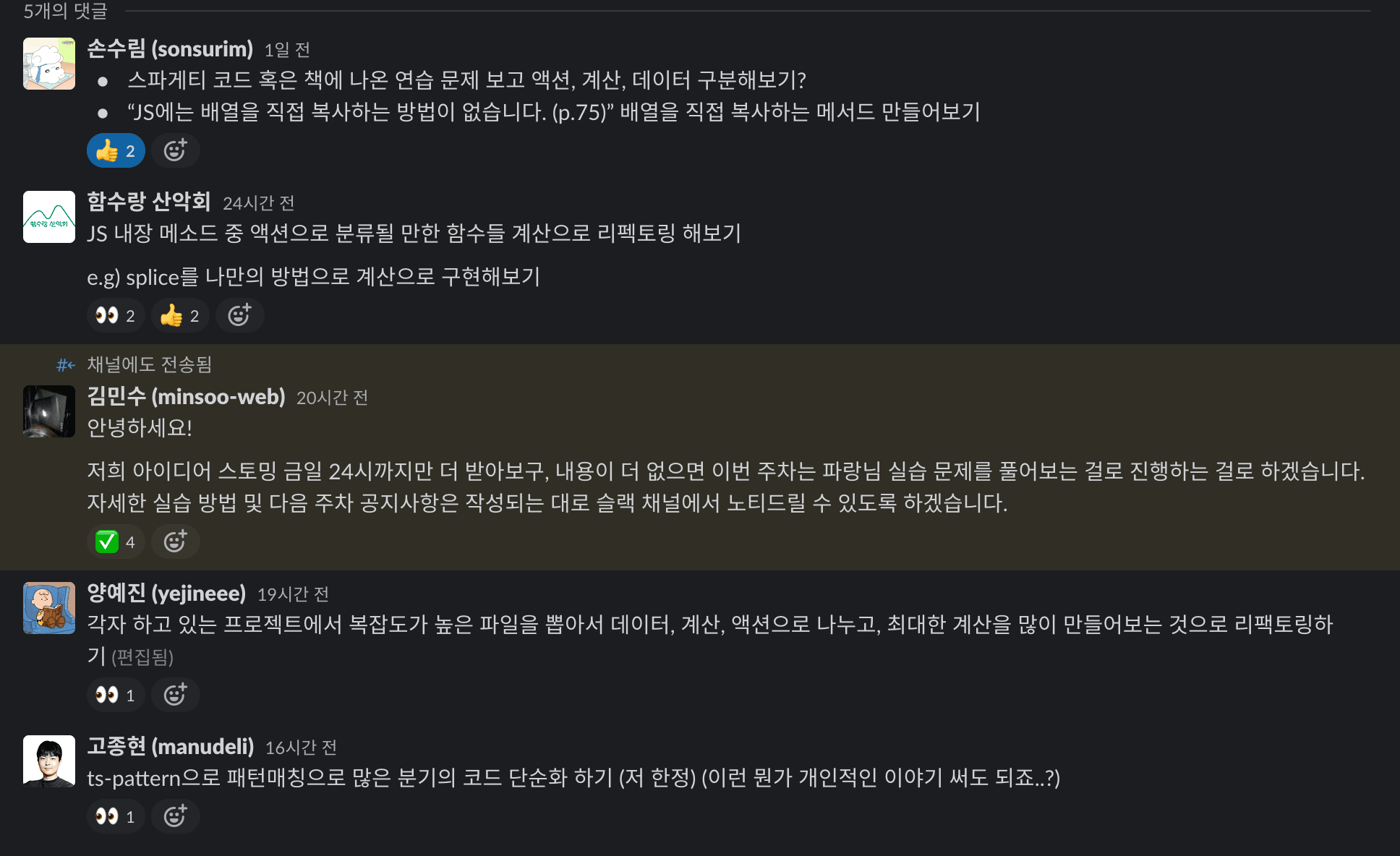
-
2회차 아이디어 스토밍
민수- 6장에서 (p122) 읽기도 하면서 쓰기도 하는 함수를 개선하는 내용이 있다. shift 외에도 이런 내장 함수가 있었나? 있다면 그것도 바꿔보거나 shift를 나만의 방식으로 개선해보자
- 파랑님 문제중에 deepCopy 직접 구현하는 문제가 있는데 그거 꼭 풀어보자!
수림- 이번에는 책에 나온 실습 문제 풀어봐도 좋겠다.
종현- 람다와 같은 함수형 도구들이 있다.
- 하나도 제대로 사용해본 적이 없다. → 제대로 사용해보자 (람다든, 뭐든 함수형 도구!)
예진- 얼랭과 엘릭서에서 방어적 복사를 어떻게 구현하였는지 살펴보기.
Check out 🚪
- 민수(김)
- 뿌듯했다. 시간 안에 끝냈다!
- 수림
- 오늘도 넘 재밌었다!!
- 좋았던 부분은 비슷한 내용이 많아서 (내 시간에) 논의하고 싶은 부분에 대한 이야기를 길게 해도 괜찮을 것 같다는 생각이 든다!
- 논의하고 싶은 부분에서 인사이트를 많이 얻은 것 같다
- 종현
- 코테를 잘 볼 수 있을 거 같다
- 예진
- 대립적인 이야기를 하는 걸 좋아한다. 오늘 많이 나와서 좋았다!
- 민수(박)
- 책을 읽고 참여하는 건 처음 참여했는데
- 비순수함수 → 액션
- 방어적 복사, 암묵적 입력 과 같이 책이 표현하는 방식들이 좋았던 것 같다.
- 같이 그런 내용들을 기반으로 얘기하니까 좋았다
[2주차] 쏙쏙쑥쑥 스터디 만족도 조사 (opens in a new tab)
이번 설문조사는 항목이 추가되었습니다! ㅠㅠ 더 나은 스터디 진행을 위해 질문 드리는 내용이니, 작성 한 번씩 부탁드립니다..!